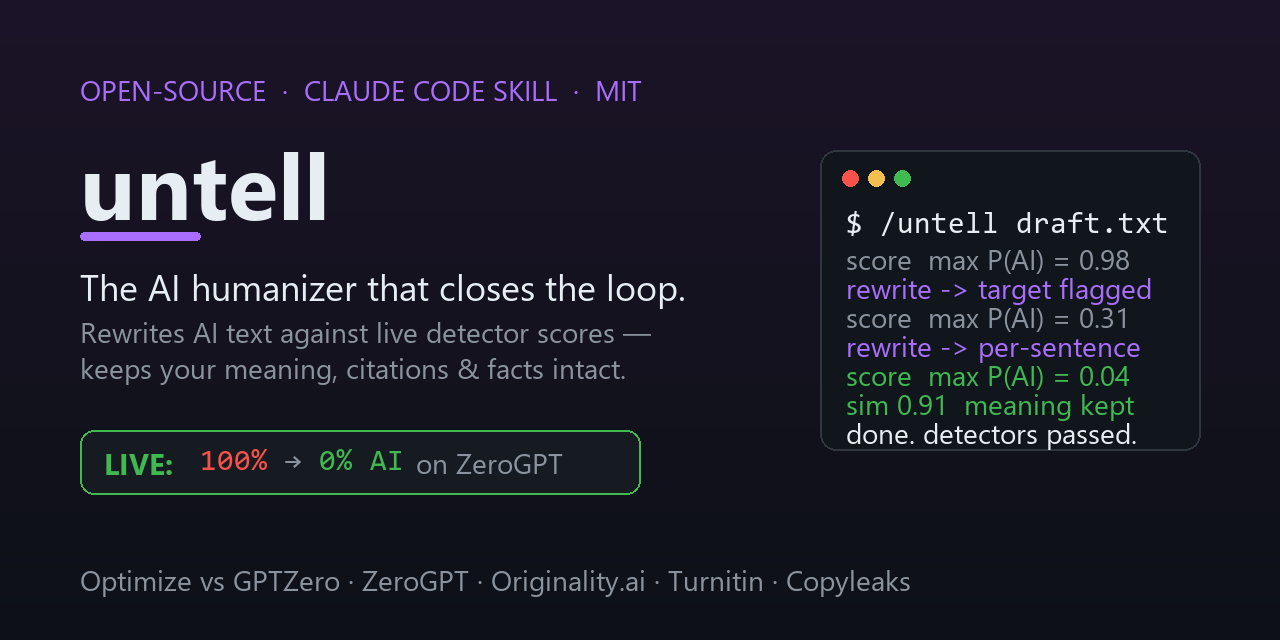

Most "AI humanizers" do one blind paraphrase pass and plateau at 60–80% detector bypass. This one runs a loop: it scores your text against an ensemble of real AI detectors, rewrites using each detector's score as feedback (targeting the exact sentences that read as AI), and re-scores — repeating until the hardest detector stops flagging it and a semantic-similarity gate confirms your meaning is unchanged. That detector-feedback approach is the strongest training-free technique in the published literature — and no shipping tool, open or commercial, actually ships it.
a stickier one went 100% → 35% → 0% once the loop used per-sentence feedback.
Quick start
As a Claude Code skill (zero install):
git clone https://github.com/ssamba1/untell
cp -r untell/untell ~/.claude/skills/untell
# then in Claude Code:
/untell <your text or a file path>As a Python CLI:
pip install -e ".[full]"
untell-loop "Your AI-sounding paragraph here." # rewrite until it passes
untell-verify --file draft.txt # honest pass/fail per detectorWhy it works where blind paraphrasers fail
Drives the max
Optimizes the hardest detector across the whole ensemble, not the average — genuine multi-detector evasion.
Meaning-gated
A 0.76 semantic-similarity bar rejects any rewrite that drifts. It refuses the meaning-mangling other tools ship.
Facts locked
Citations, numbers, quotes, URLs and entities are frozen byte-for-byte. Your APA/IEEE references survive untouched.
Per-sentence
Rewrites only the sentences that read as AI — fewer iterations, less drift, higher pass rate.
The most complete open humanizer
We surveyed ~110 open-source humanizer repos. None combine all four of: a real evasion approach validated against multiple live detectors, a meaning-preservation verifier, an inference-time detector-feedback loop, and a user-installable package. This is the repo that does.
| Capability | untell | lynote (1.4k★) | patina (196★) | StealthHumanizer (58★) |
|---|---|---|---|---|
| Detector-feedback loop | ✅ | ❌ | ◑ | ◑ |
| Real detectors in the loop | ✅ | ❌ | ❌ | ❌ |
| Commercial adapters (6) | ✅ | ❌ | ❌ | ❌ |
| Semantic meaning gate | ✅ | claim | ◑ | ◑ |
| Live bypass proof | ✅ | ❌ | ❌ | ❌ |
| pip + Claude skill | ✅ | pip | ✅ | web app |
Stars are not capability — the highest-starred repos win on SEO, not architecture. Full evidenced breakdown (and the one place we're honestly not #1): docs/why-best-open-repo.md.
FAQ
Is there a free AI humanizer that actually works?
Yes — the lite tier installs with zero dependencies and the --browser zerogpt path optimizes against a real detector for $0 (live-measured 100%→0%). No tool can honestly promise it passes every commercial detector forever; the ones claiming "99% human" are lying. untell reports the real per-detector score instead.
Does it bypass GPTZero / ZeroGPT / Turnitin / Originality.ai?
It optimizes and verifies against them. ZeroGPT is built into the free browser path and live-proven. GPTZero, Originality.ai, Turnitin-class, Copyleaks, Winston and Sapling are key-gated commercial adapters; the loop drives the max across every checker you configure. Originality.ai is the hardest — we don't claim to beat it without your key to prove it.
Will it ruin my meaning, citations or numbers?
No. A semantic-similarity gate rejects meaning-drifting rewrites and preserve-lock freezes citations, numbers, quotes, URLs and entities byte-for-byte. Good for academic, legal and ESL writing.
How is it different from Undetectable.ai / QuillBot / WriteHuman?
Those are closed SaaS doing a single blind pass with a fake binary verdict. untell is open source, runs a closed detector-feedback loop, optimizes against multiple real detectors, gates on meaning, and gives an honest reproducible score you can audit.
Is this ethical?
AI detectors are noisy proxies — they falsely flag non-native English writers at ~61% in some studies. untell is a research harness and a defense against false positives, not an academic-dishonesty aid.